Marginalia — Cuaderno Interactivo Capítulo 1 — Linear regression with one predictor variable
Table of Contents
- Índices de Navegación / Navigation Indexes
- Resumen
- 1.1 Relaciones entre variables
- 1.2 Regression models and their uses
- Construccion de modelos de regresion
- 1.3 Simple linear regression model with distribution of error terms unspecified
- 1.4 Datos para el análisis de regresión
- 1.5 Vision general de los pasos en el analisis de regresion
- 1.6 Estimation of Regression Function
Índices de Navegación / Navigation Indexes
Resumen
Introducción al análisis de regresión lineal simple. Se establece la distinción fundamental entre relaciones funcionales (matemáticas exactas) y estadísticas (con dispersión aleatoria), sentando las bases teóricas y visuales para el estudio de modelos con una sola variable predictora.
Notas de lectura sobre \citet{kutner2004}, capítulo 1.
:CUSTOMID: capitulo-1-regresion-lineal
1.1 Relaciones entre variables
Relación funcional vs. relación estadística
En el análisis de regresión se distingue fundamentalmente entre dos tipos de relaciones:
- Relación funcional: se expresa mediante una fórmula matemática exacta. Si \(X\) es la variable independiente y \(Y\) la dependiente, la relación es de la forma \(Y = f(X)\) — todos los puntos de observación caen directamente sobre la curva.
- Relación estadística: a diferencia de la funcional, no es perfecta. Las observaciones presentan una dispersión ("scattering") de naturaleza aleatoria alrededor de la curva. Un diagrama de dispersión (scatter plot) es la herramienta básica para visualizarla; cada punto representa un "caso" o ensayo.
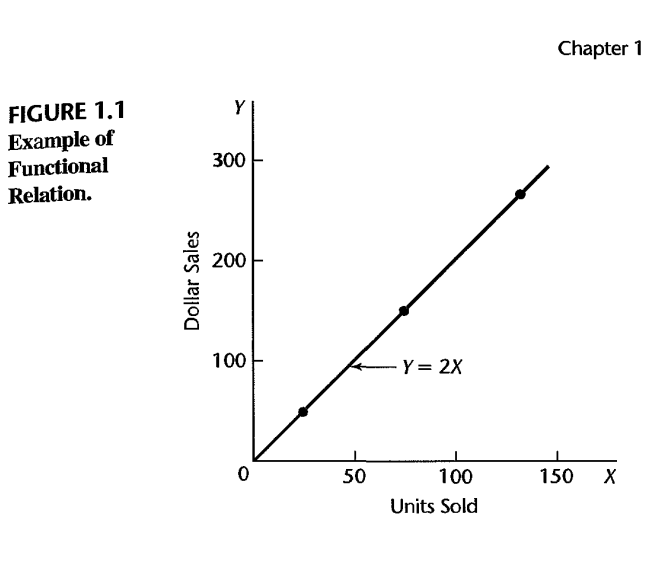
Ejemplo de relación funcional
Considere la relación entre las ventas en dólares (\(Y\)) de un producto vendido a un precio fijo y el número de unidades vendidas (\(X\)). Si el precio de venta es de \$2 por unidad:
Y = 2X
El número de unidades vendidas y las ventas en dólares durante tres períodos recientes (precio unitario constante en \$2) fueron:
| Período | Unidades vendidas | Ventas en dólares |
|---|---|---|
| 1 | 75 | 150 |
| 2 | 25 | 50 |
| 3 | 130 | 260 |
Todas las observaciones caen directamente sobre la línea — característico de toda relación funcional.
Grafico de la relacion funcional
Relación estadística entre dos variables
Una relación estadística, a diferencia de una funcional, no es perfecta: en general, las observaciones no caen directamente sobre la curva de relación.
Ejemplo 1 — Evaluaciones de desempeño
Se obtuvieron evaluaciones de desempeño para 10 empleados a mediados de año y al final del año. Las evaluaciones de fin de año se tomaron como la variable dependiente \(Y\), y las de mitad de año como la predictora \(X\).
- Grafico 1-2
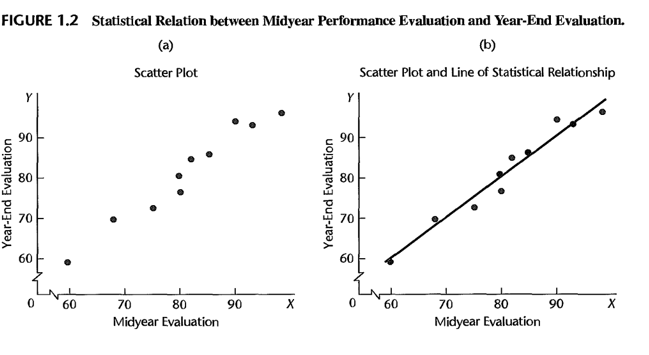
La variable \(X\) representa la evaluación de mitad de año, actuando como predictor en este modelo. La observación del primer empleado se localiza en \((X=90, Y=94)\).
- Figura 1.2a — diagrama de dispersión
Evidencia una relación estadística positiva: a medida que aumenta \(X\), tiende a aumentar \(Y\), pero la relación no es determinista. La dispersión de puntos indica que la variación en \(Y\) no es explicada en su totalidad por \(X\) — por ejemplo, los empleados con \(X=80\) comparten el mismo nivel intermedio pero sus resultados finales difieren ligeramente. Cada punto del diagrama es un ensayo o caso individual; la dispersión es el sello distintivo de una relación estadística, a diferencia de una funcional exacta.
- Figura 1.2b — línea de relación estadística
La línea superpuesta modela la tendencia general de los datos, pero la mayoría de las observaciones no caen exactamente sobre ella. La distancia vertical entre cada punto y la línea representa el error o variación no explicada — la variabilidad en \(Y\) no asociada con \(X\), considerada de naturaleza aleatoria.
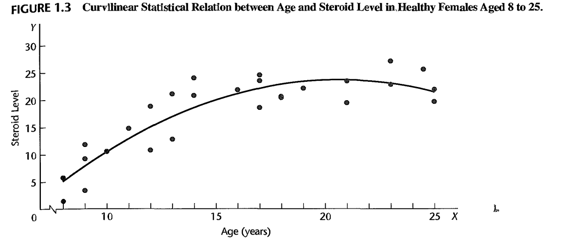
Ejemplo 2 — relación curvilínea
La Figura 1.3 presenta datos sobre la edad y el nivel de un esteroide en plasma para 27 mujeres sanas entre 8 y 25 años. Los datos sugieren una relación estadística curvilínea (no lineal): el nivel de esteroide aumenta con la edad hasta un punto (≈15–16 años) y luego se estabiliza.
1.2 Regression models and their uses
Orígenes históricos
El análisis de regresión fue desarrollado inicialmente por Sir Francis Galton a finales del siglo XIX, a partir de su estudio de la relación entre la estatura de padres e hijos \citep{galton1886}. Observó que los hijos de padres muy altos o muy bajos tendían a tener estaturas más cercanas al promedio del grupo — un fenómeno que llamó "regresión hacia la mediocridad" (regression to mediocrity). Aunque el término original tenía una connotación específica sobre la estatura, hoy persiste para describir cualquier relación estadística entre variables.
Profundicé en el trabajo original de Galton —los experimentos con semillas, la Tabla I, las elipses de frecuencia, la ecuación de equilibrio poblacional— en una pieza aparte:
Excursus: Galton y el origen de la regresión a la mediocridad
Conceptos básicos del modelo de regresión
Un modelo de regresión formaliza dos ingredientes esenciales de una relación estadística:
- Una tendencia de la variable de respuesta \(Y\) a variar con la variable predictora \(X\) de manera sistemática.
- Una dispersión de puntos alrededor de la curva de relación estadística.
Para incorporar ambos, los modelos de regresión postulan:
- Distribución de probabilidad: para cada nivel de \(X\) existe una distribución de probabilidad de \(Y\) — esto explica la dispersión, ya que \(Y\) no es un valor único para un \(X\) dado, sino una variable aleatoria.
- Variación sistemática de las medias: los valores medios (esperanzas) de esas distribuciones varían sistemáticamente con \(X\) — esto explica la tendencia; la línea de regresión representa la trayectoria de esas medias a medida que \(X\) cambia.
Esto se ilustra en la Figura 1.2: la línea representa la media de la distribución de \(Y\) para cada \(X\), y los puntos dispersos representan las realizaciones individuales de esa distribución.
Ejemplo:
Considramos nuevamente el ejemplo de evalucion del rendimiento en la Figura 1.2. La evaluacion de fin de año Y se trata en un modelo de regresion como una variable aleatoria. Para cada nivel de evaluacion del rendimiento de mitad de año, se postula una distribucion de probabilidad de Y. La figura 1.4 muestra dicha distribucion de probabilidad para X = 90, que es la evaluacion de mitad de año para el primer empleado.
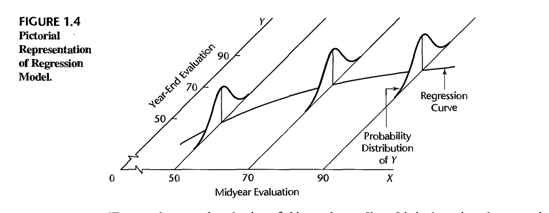
Los modelos de regresion con mas de una variable predictiva.
- En un estudio de eficiencia de 67 sucursales de una cadena de finanzas al consumo, la variable de respuesta fue el costo operativo directo para el año anterior. Había cuatro variables predictoras: tamaño promedio del préstamo pendiente durante el año, número promedio de préstamos pendientes, número total de solicitudes de préstamos procesadas y un índice de salarios de oficina.
- En un estudio de compra de tractores, la variable de respuesta fue el volumen (en caballos de fuerza) de las compras de tractores en un territorio de ventas de una empresa de equipos agrícolas. Había nueve variables predictoras, incluyendo la edad promedio de los tractores en las granjas del territorio, número de granjas en el territorio y un índice de cantidad de producción de cultivos en el territorio.
- En un estudio médico de niños de baja estatura, la variable de respuesta fue el nivel máximo de hormona de crecimiento en plasma. Había 14 variables predictoras, incluyendo edad, género, altura, peso y 10 mediciones de pliegues cutáneos.
Construccion de modelos de regresion
Seleccion de Variables Predictoras
El Dilema de la Reducción de la Realidad La construcción de un modelo de regresión no es un ejercicio puramente matemático, sino un acto de simplificación epistemológica.
- Premisa Fundamental: La realidad es infinitamente compleja; un modelo debe ser "manejable" para ser útil.
- El Reto: Reducir la complejidad del fenómeno real a un conjunto finito de variables y una estructura funcional específica sin perder la esencia explicativa del fenómeno.
- Objetivo del Modelador: Encontrar el equilibrio óptimo entre la complejidad del modelo (sobreajuste) y la capacidad explicativa (subajuste o sesgo).
- Selección de Variables Predictoras (\(X\))
2.1. El Problema Central en Estudios Exploratorios En la mayoría de los estudios aplicados, el conjunto de variables candidatas es vasto. El problema central es seleccionar un subconjunto \(S \subset \{X_1, X_2, \dots, X_k\}\) que sea "bueno" para el propósito específico del análisis.
- Definición de "Bueno": No existe una definición universal; depende del objetivo (predicción, inferencia causal, control).
- Criterio de Inclusión: La decisión de incluir una variable \(X_j\) no debe basarse en su correlación marginal con \(Y\), sino en su contribución marginal.
Forma Funcional de la Relacion de Regresion.
Esta relacion esta vinculada a la eleccion de las variables predictoras. Algunas ocasiones, la teoria relevante puede indicar la forma funcional adecuada. La teoria del aprendizaje, por ejemplo, puede indicar que la funcion de regresion que relacional el costo de produccion unitario con el numero de veces que se ha producido el articulo anteriormente debe tener una forma especifica con propiedades asintoticas particulares.Con mayor frecuencia, sin embargo, la forma funcional de la relación de regresión no se conoce de antemano y debe decidirse empíricamente una vez que se hayan recopilado los datos. Las funciones de regresión lineales o cuadráticas a menudo se utilizan como aproximaciones satisfactorias a funciones de regresión de naturaleza desconocida. De hecho, estos tipos simples de funciones de regresión pueden utilizarse incluso cuando la teoría proporciona la forma funcional relevante, notablemente cuando la forma conocida es muy compleja pero se puede aproximar razonablemente con una función de regresión lineal o cuadrática.
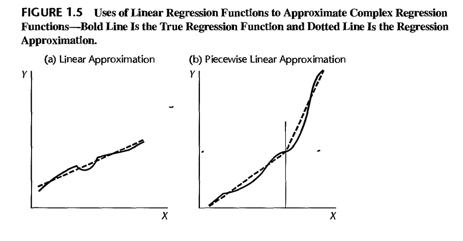
Alcance del modelo
El alacance se determina o por el diseño de la investigacion o por el rango de de datos disponibles. Por ejemplo, una empresa que estudia el efecto de precio en el volumen de ventas unvestigo seis niveles de precio, que variaban desde $4.95 hasta $6.95. Aqui el alcance de un modelo se limita a niveles de precio que van desde alrededor de $5 hasta alrededor de $7. La forma de la funcion de regresion sustancialmente fuera de este rango estaria en serias dudas porque la investigacion no proporciono nninguna evidencia sobre la naturaleza de la relacion estadistica por debajo de $4.95 o por encima de $6.95.
Usos del analisis de regresion
El análisis de regresión sirve para tres propósitos principales: (I) descripción, (2) control y (3) predicción. Estos propósitos se ilustran con los tres ejemplos citados anteriormente. El estudio de la compra de tractores tuvo un propósito descriptivo. En el estudio de los costos de operación de las oficinas sucursales, el propósito principal era el control administrativo; al desarrollar una relación estadística utilizable entre el costo y las variables predictoras, la gerencia pudo establecer estándares de costo para cada oficina sucursal en la cadena de la empresa. En el estudio médico de los niños de baja estatura, el propósito era la predicción. Los clínicos pudieron utilizar la relación estadística para predecir deficiencias de hormona del crecimiento en niños de baja estatura mediante simples mediciones de los niños. Los varios propósitos del análisis de regresión a menudo se superponen en la práctica. El ejemplo de la oficina sucursal es un caso en punto. El conocimiento de la relación entre el costo de operación y las características de la oficina sucursal no solo permitió a la gerencia establecer estándares de costo para cada oficina, sino que también pudo predecir los costos, y al final del año fiscal, pudo comparar el costo real de la oficina sucursal con el costo esperado.
Regresion y Causalidad
La existencia de una relación estadística entre la variable de respuesta Y y la variable explicativa o predictora X no implica de ninguna manera que Y dependa causalmente de X. No importa cuán fuerte sea la relación estadística entre X e Y, no se implica necesariamente un patrón de causa-efecto por el modelo de regresión. Por ejemplo, los datos sobre el tamaño del vocabulario (X) y la velocidad de escritura (Y) para una muestra de niños pequeños de 5-10 años mostrarán una relación de regresión positiva. Sin embargo, esta relación no implica que un aumento en el vocabulario cause una mayor velocidad de escritura. Aquí, otras Variables explicativas, como la edad del niño y la cantidad de educación, afectan tanto el vocabulario (X) como la velocidad de escritura (Y). Los niños mayores tienen un vocabulario más grande y una mayor velocidad de escritura.
Estos ejemplos demuestran la necesidad de cuidado al sacar conclusiones sobre relaciones causales a partir del análisis de regresión. El análisis de regresión por sí solo no proporciona información sobre patrones causales y debe ser complementado con análisis adicionales para obtener conocimientos sobre relaciones causales.
Uso de computadoras
Dado que el análisis de regresión a menudo implica cálculos largos y tediosos, las computadoras suelen utilizarse para realizar los cálculos necesarios. Casi todos los paquetes estadísticos para computadoras contienen un componente de regresión. Aunque los paquetes difieren en muchos detalles, su salida básica de regresión tiende a ser bastante similar.
1.3 Simple linear regression model with distribution of error terms unspecified
Declaracion pormal del modelo
En la Parte I consideramos un modelo de regresión básico donde solo hay una variable predictor y la función de regresión es lineal. El modelo se puede enunciar de la siguiente manera:
El modelo se define formalmente como:
\[ Y_i = \beta_0 + \beta_1 X_i + \varepsilon_i \]
Donde:
- \(Y_i\) es el valor de la respuesta en el \(i\)-ésimo ensayo.
- \(\beta_0\) y \(\beta_1\) son los parámetros (coeficientes de regresión). \(\beta_1\) es la pendiente y \(\beta_0\) la intersección en \(Y\).
- \(X_i\) es una constante conocida (el valor de la predictora).
- \(\varepsilon_i\) es el término de error aleatorio, con \(E\{\varepsilon_i\} = 0\) y varianza constante \(\sigma^2\{\varepsilon_i\} = \sigma^2\). Los errores de distintos ensayos no están correlacionados (covarianza cero).
Características clave:
- \(Y_i\) es una variable aleatoria con media \(E\{Y_i\} = \beta_0 + \beta_1 X_i\).
- La función de regresión es \(E\{Y\} = \beta_0 + \beta_1 X\).
- La varianza de \(Y_i\) es \(\sigma^2\), la misma para todos los niveles de \(X\) (homocedasticidad).
Caracteristicas importantes del modelo
- La respuesta Y; en el ensayo iésimo es la suma de dos componentes: (1) el término constante
\(f_{30} + f_{31} X_i\) y (2) el término aleatorio \(\varepsilon_i\). Por lo tanto, \(Y_i\) es una variable aleatoria.
- Dado que \(E\{\varepsilon_i\} = 0\), se deduce de \((A.13c)\) en el Apéndice A que:
\(E\{Y_i\} = E\{f_{30} + f_{31} X_i + \varepsilon_i\} = f_{30} + f_{31}X_i + E\{\varepsilon_i\} = f_{30} + f_{31}X_i\) Observe que \(f_{30} + f_{31}X_i\) desempeña el papel de la constante \(a\) en \((A.13c)\).
Por lo tanto, la respuesta \(Y_i\), cuando el nivel de \(X\) en el ensayo $i$-ésimo es \(X_i\), proviene de una distribución de probabilidad cuya media es: \[E\{Y_i\} = \beta_0 + \beta_1 X_i\] (1.2)
Por lo tanto, sabemos que la función de regresión para el modelo (1.1) es: \[E\{Y\} = \beta_0 + \beta_1 X\] (1.3)
ya que la función de regresión relaciona las medias de las distribuciones de probabilidad de \(Y\) para un \(X\) dado con el nivel de \(X\).
- La respuesta \(Y_i\) en el ensayo $i$-ésimo supera o queda por debajo del valor de la función de regresión por la cantidad del término de error \(\varepsilon_i\).
- Se asume que los términos de error \(\varepsilon_i\) tienen una varianza constante \(\sigma^2\). Por lo tanto, se deduce que las respuestas \(Y_i\) tienen la misma varianza constante:
\[\sigma^2\{Y_i\} = \sigma^2\] (1.4)
ya que, utilizando (A.16a), tenemos: \[\sigma^2\{\beta_0 + \beta_1 X_i + \varepsilon_i\} = \sigma^2\{\varepsilon_i\} = \sigma^2\]
Por lo tanto, el modelo de regresión (1.1) asume que las distribuciones de probabilidad de \(Y\) tienen la misma varianza \(\sigma^2\), independientemente del nivel de la variable predictora \(X\).
- Se asume que los términos de error no están correlacionados. Dado que los términos de error \(\varepsilon_i\) y \(\varepsilon_j\) no están correlacionados, también lo están las respuestas \(Y_i\) y \(Y_j\).
- En resumen, el modelo de regresión (1.1) implica que las respuestas \(Y_i\) provienen de distribuciones de probabilidad cuyas medias son \(E\{Y_i\} = \beta_0 + \beta_1 X_i\) y cuyas varianzas son \(\sigma^2\), las mismas para todos los niveles de \(X\). Además, dos respuestas cualesquiera \(Y_i\) y \(Y_j\) no están correlacionadas.
Ejemplo
Un consultor de un distribuidor eléctrico está estudiando la relación entre el número de licitaciones solicitadas por contratistas de construcción para equipos de iluminación básica durante una semana y el tiempo requerido para preparar dichas licitaciones. Suponga que el modelo de regresión (1.1) es aplicable y es el siguiente:
\[Y_i = 9.5 + 2.1 X_i + \varepsilon_i\]
donde \(X\) es el número de licitaciones preparadas en una semana y \(Y\) es el número de horas requeridas para preparar las licitaciones. La Figura 1.6 contiene una presentación de la función de regresión: \[E\{Y\} = 9.5 + 2.1 X\]
Suponga que en la semana $i$-ésima se preparan \(X_i = 45\) licitaciones y el número real de horas requeridas es \(Y_i = 108\). En ese caso, el valor del término de error es \(\varepsilon_i = 4\), ya que tenemos:
\[E\{Y_i\} = 9.5 + 2.1(45) = 104\]
y
\[Y_i = 108 = 104 + 4\]
Significado de los Parámetros y Visualización del Modelo
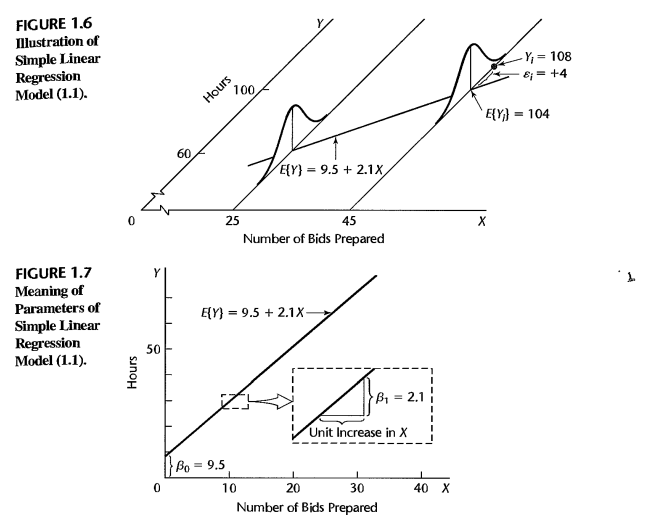
Figure 1: Ilustración del Modelo de Regresión Lineal Simple e Interpretación de Parámetros (Kutner et al., 2004).
Para abrir o inspeccionar la captura original directamente en tu entorno, utiliza el siguiente hipervínculo interactivo: Ver captura original de las Figuras 1.6 y 1.7.
Explicación Teórica de los Puntos Clave
De acuerdo con la formalización presentada en la página 11 del texto guía, las representaciones gráficas sintetizan los supuestos fundamentales del modelo de regresión lineal simple:
- El Supuesto de Homocedasticidad (Figura 1.6): La gráfica tridimensional ilustra que para cualquier nivel fijado de la variable predictora \(X\) (por ejemplo, en las semanas con \(X = 25\) o \(X = 45\) licitaciones), la respuesta \(Y\) se distribuye de manera Gaussiana o normal. Un requerimiento indispensable es que cada una de estas distribuciones de probabilidad posea exactamente la misma variabilidad intrínseca (varianza constante \(\sigma^2\)).
- El Margen de Desviación Aleatoria: El punto observado real \(Y_i = 108\) asociado a la semana con \(X_i = 45\) se desvía de su valor esperado sobre la recta (\(E\{Y_i\} = 104\)) por un factor de perturbación estocástica denominado error aleatorio o residuo, expresado analíticamente en este punto empírico como \(\varepsilon_i = +4\).
- Interpretación de los Coeficientes (Figura 1.7):
- El parámetro \(\beta_1 = 2.1\) determina la pendiente de la función de regresión e indica que la preparación de una licitación complementaria genera un aumento de exactamente 2.1 horas en la media de la distribución de probabilidad de la respuesta \(Y\).
- El intercepto \(\beta_0 = 9.5\) representa el valor esperado del modelo en el origen geométrico (\(X = 0\)). Como el alcance real del muestreo de la distribuidora eléctrica rara vez incluye semanas con cero licitaciones, este coeficiente funciona estrictamente como un soporte de anclaje matemático para proyectar la recta, careciendo de un significado práctico aislado dentro del contexto de la operación corporativa.
- El parámetro \(\beta_1 = 2.1\) determina la pendiente de la función de regresión e indica que la preparación de una licitación complementaria genera un aumento de exactamente 2.1 horas en la media de la distribución de probabilidad de la respuesta \(Y\).
Significado de los parametros de regresion
El modelo de regresión lineal simple no es una simple línea recta geométrica; es un modelo estadístico condicional. Esto significa que describe cómo cambia una variable aleatoria completa a medida que modificamos el valor de otra.
La ecuación del modelo se define formalmente como: \[Y_i = \beta_0 + \beta_1 X_i + \varepsilon_i\]
Donde cada componente describe una propiedad matemática de las campanas de Gauss que ves en la gráfica:
- La Media Condicional (\(E\{Y_i\}\)): La línea recta une los centros exactos de todas las campanas de Gauss. Para cualquier nivel específico \(X_i\), el valor esperado o promedio de la respuesta es: \[E\{Y_i\} = \beta_0 + \beta_1 X_i\] En el ejemplo, cuando se preparan \(X = 45\) licitaciones, el tiempo promedio que le toma al distribuidor es exactamente de \(9.5 + 2.1(45) = 104\) horas. No significa que siempre tardará 104 horas, sino que si observamos muchas semanas con 45 licitaciones, el promedio de todas ellas convergerá a 104.
- El Error Aleatorio (\(\varepsilon_i\)): Representa la distancia vertical entre el punto real observado (\(Y_i\)) y la recta teórica (\(E\{Y_i\}\)).
- En la gráfica se aprecia un caso real: una semana en la que se prepararon \(X_i = 45\) licitaciones y el tiempo real medido fue \(Y_i = 108\) horas.
- La desviación o residuo para esa semana específica es: \[\varepsilon_i = Y_i - E\{Y_i\} = 108 - 104 = +4\text{ horas}\]
- Este \(+4\) captura todo lo que la variable \(X\) no puede explicar: imprevistos logísticos, problemas con el personal, cortes de energía o variabilidad humana interna de esa semana en particular.
- El Supuesto de Homocedasticidad (\(\sigma^2\)): Observa que el ancho y la dispersión de la campana en \(X = 25\) es idéntica a la campana en \(X = 45\). Matemáticamente, la varianza del error es constante: \[\sigma^2\{\varepsilon_i\} = \sigma^2\] Esto implica que la incertidumbre o el "riesgo de error" del negocio es exactamente el mismo cuando el volumen de trabajo es bajo que cuando es alto.
Los coeficientes de regresión (\(\beta_0\) y \(\beta_1\)) transforman las dimensiones físicas del problema (Licitaciones) en unidades de la variable respuesta (Horas).
- La Pendiente (\(\beta_1 = 2.1\)): Es una tasa de cambio fundamental (\(\Delta Y / \Delta X\)).
- Su unidad de medida es \(\text{Horas}/\text{Licitación}\).
- Indica que por cada licitación extra que el distribuidor decida preparar en una semana, el tiempo promedio esperado de trabajo se incrementará en \(2.1\) horas.
- Gráficamente, el "escalón" punteado de la Figura 1.7 muestra que si avanzamos \(1\) unidad a la derecha en el eje \(X\), la recta se eleva verticalmente \(2.1\) unidades en el eje \(Y\).
- El Intercepto (\(\beta_0 = 9.5\)): Representa el valor donde la recta corta el eje vertical (\(Y\)), es decir, el valor esperado de \(Y\) cuando \(X = 0\).
- Su unidad de medida son \(\text{Horas}\).
- Peligro de Extrapolación: El autor advierte que si el alcance del estudio no incluye semanas con cero licitaciones, interpretar este \(9.5\) como "el tiempo que se gasta si no se hace nada" es un error metodológico. Frecuentemente, el intercepto actúa solo como una constante de ajuste matemático para posicionar correctamente la inclinación de la recta en la zona donde sí tenemos datos reales.
Versiones alternativas al modelo de regresion
A veces resulta matemáticamente conveniente reescribir el modelo de regresión lineal simple en formas distintas pero algebraicamente equivalentes, utilizándolas de manera intercambiable según la conveniencia del cálculo.
Podemos asociar formalmente una variable \(X\) a cada uno de los coeficientes de regresión del modelo. Si definimos una constante \(X_0\) que sea idénticamente igual a 1, el modelo se expresa como:
\[Y_i = \beta_0 X_0 + \beta_1 X_i + \varepsilon_i\] \[\text{donde } X_0 \equiv 1\]
> Utilidad: Esta formulación es la piedra angular del álgebra matricial de la regresión lineal multivariada, ya que permite estructurar el intercepto \(\beta_0\) dentro del mismo vector de variables predictoras.
1.4 Datos para el análisis de regresión
En la práctica, los parámetros de regresión \(\beta_0\) y \(\beta_1\) del modelo (1.1) son desconocidos y deben ser estimados a partir de datos relevantes. Es común carecer de conocimiento a priori sobre cuáles son las variables predictoras apropiadas o la forma funcional correcta (lineal o curvilínea), por lo que se depende del análisis exploratorio de datos para desarrollar un modelo adecuado.
Los datos para un análisis de regresión se obtienen principalmente a través de dos metodologías de investigación:
- Estudios no experimentales (Datos Observacionales).
- Estudios experimentales (Datos Experimentales).
Datos Observacionales (Estudios No Experimentales)
Los datos observacionales se recolectan en entornos donde el investigador no tiene control sobre las variables explicativas o predictoras de interés.
- Ejemplo del Texto: Una empresa desea estudiar la relación entre la edad de los empleados (\(X\)) y los días de enfermedad el año pasado (\(Y\)) utilizando los registros de personal. Estos datos son estrictamente observacionales porque la edad no puede ser manipulada ni asignada por los investigadores.
- Justificación de su Uso: Son el tipo de datos más frecuente en analítica de negocios y ciencias sociales debido a que la experimentación controlada muchas veces resulta inviable o éticamente imposible (v.g., no se le puede asignar una edad a un empleado).
La Limitación Crítica: Correlación no es Causación
La mayor debilidad de los datos observacionales es que rara vez proporcionan información adecuada para establecer relaciones de causa y efecto.
- El Problema de las Variables Omitidas (Confusión): Una relación lineal positiva entre la edad y los días de enfermedad no implica que la edad sea la causa directa de la enfermedad.
- Podría ocurrir que los empleados jóvenes trabajen principalmente en interiores, mientras que los empleados mayores realicen labores a la intemperie (ubicación laboral).
- Si el ambiente exterior es el que verdaderamente enferma, la "ubicación" es la causa real, actuando como una variable confusora omitida.
- Podría ocurrir que los empleados jóvenes trabajen principalmente en interiores, mientras que los empleados mayores realicen labores a la intemperie (ubicación laboral).
- Directriz Metodológica: Al construir modelos descriptivos basados en datos observacionales, es mandatorio investigar exhaustivamente si existen variables explicativas omitidas que expliquen de forma más directa el fenómeno.
Datos Experimentales (Estudios Controlados)
Los datos experimentales se generan cuando el investigador ejerce un control activo y deliberado sobre las variables predictoras.
- Ejemplo del Texto: Una aseguradora evalúa la relación entre la productividad de sus analistas al procesar reclamaciones (\(Y\)) y la duración de su entrenamiento (\(X\)). Se seleccionan 9 analistas de forma aleatoria: 3 reciben dos semanas de entrenamiento, 3 reciben tres semanas y 3 reciben cinco semanas. La productividad posterior se mide durante 10 semanas.
El Poder de la Aleatorización (Randomization)
Cuando el control de las variables explicativas se ejecuta mediante asignación aleatoria, los datos experimentales ofrecen evidencia sustancialmente más sólida sobre relaciones de causa y efecto en comparación con los observacionales.
- Mecanismo de Balance: La aleatorización tiende a promediar y equilibrar entre los grupos el efecto de cualquier otra variable no medida que pudiera afectar la respuesta (como la aptitud innata, la motivación o la experiencia previa del analista).
Terminología del Diseño de Experimentos
- Tratamiento (Treatment): Es el nivel específico de la variable explicativa asignado a un sujeto (v.g., la duración del entrenamiento: 2, 3 o 5 semanas).
- Unidades Experimentales (Experimental Units): Son los elementos o sujetos sobre los cuales se aplican los tratamientos (v.g., los analistas de la aseguradora).
Diseño Completamente Aleatorizado (Completely Randomized Design)
Es la estructura estadística más básica para realizar asignaciones aleatorias de tratamientos a unidades experimentales. Bajo este enfoque, las asignaciones se realizan completamente al azar, garantizando que todas las combinaciones posibles de unidades asignadas a los tratamientos sean igualmente probables. Esto implica que cada sujeto tiene exactamente la misma probabilidad matemática de recibir cualquier tratamiento.
Ventajas y Desventajas Metodológicas
- *Ventajas:
- Flexibilidad Absoluta: Permite acomodar cualquier cantidad de tratamientos.
- Tamaños de Muestra Variables: No exige que todos los tratamientos tengan el mismo número de réplicas o unidades (admite muestras desiguales).
- Idoneidad para Homogeneidad: Es óptimo cuando las unidades experimentales son muy similares entre sí.
- Desventajas:
- Ineficiencia ante Heterogeneidad: Si las unidades experimentales son muy diversas u heterogéneas (por ejemplo, analistas con niveles de educación drásticamente distintos), este diseño pierde potencia estadística frente a estructuras más avanzadas como el diseño en bloques aleatorizados.
1.5 Vision general de los pasos en el analisis de regresion
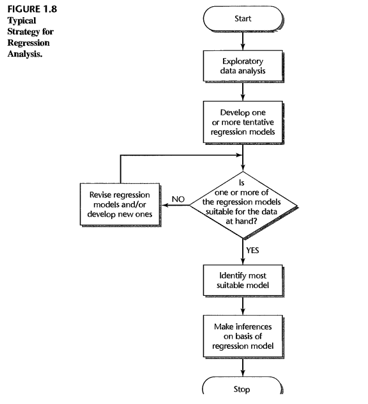
Figure 2: Diagrama de flujo de la estrategia típica para el desarrollo de modelos de regresión (Kutner et al., 2004).
Para inspeccionar o abrir el diagrama de flujo del proceso analítico, utiliza este hipervínculo interactivo: Ver diagrama de flujo original (Figura 1.8).
Ámbito de Aplicación de los Modelos
Los modelos de regresión estructurados en este texto son directamente aplicables tanto a datos observacionales como a datos experimentales provenientes de un diseño completamente aleatorizado. El análisis también puede expandirse a otros diseños experimentales más sofisticados, pero en esos escenarios las ecuaciones base presentadas requerirán modificaciones específicas.
> La Condición Sine Qua Non: Independientemente del origen de los datos (observacionales o experimentales), el requisito fundamental e ineludible para que cualquier inferencia sea válida es que las condiciones y supuestos del modelo de regresión se ajusten de manera apropiada a la naturaleza de los datos reales que se tienen a la mano.
1.6 Estimation of Regression Function
Resumen
El documento aborda los fundamentos metodológicos para estimar los parámetros de una función de regresión lineal simple.
- Naturaleza de los Datos: Se fundamenta en observaciones empíricas o experimentales compuestas por pares ordenados \((X_i, Y_i)\), donde \(X\) representa la variable predictora o explicativa e \(Y\) representa la variable de respuesta. Cada ensayo o prueba \(i\) (desde \(i = 1, \dots, n\)) genera una observación conjunta.
- Ejemplo de Persistencia: Se ilustra mediante un estudio a pequeña escala con \(n = 3\) sujetos enfrentados a una tarea difícil. Se registran las variables de edad (\(X\)) y número de intentos antes de rendirse (\(Y\)). Esto sirve para ejemplificar la asignación formal de la notación matemática a observaciones reales, como \((X_1, Y_1) = (20, 5)\).
- El Criterio de Mínimos Cuadrados: Se introduce el Método de Mínimos Cuadrados (OLS) con el objetivo de hallar estimadores óptimos ("buenos") denominados \(b_0\) y \(b_1\) para los parámetros poblacionales \(\beta_0\) y \(\beta_1\). El procedimiento matemático evalúa la desviación de cada valor observado \(Y_i\) respecto a su valor esperado, minimizando de forma agregada la suma de los cuadrados de dichas desviaciones mediante un criterio de optimización denotado como \(Q\).
"To find 'good' estimators of the regression parameters β0 and β1, we employ the method of least squares." – Michael H. Kutner et al., Applied Linear Statistical Models (5th ed.), Pág. 15.
"According to the method of least squares, the estimators of β0 and β1 are those values b0 and b1, respectively, that minimize the criterion Q for the given sample observations…" – Michael H. Kutner et al., Applied Linear Statistical Models (5th ed.), Pág. 15.
Metodo de minimos cuadrados
Para estructurar la optimización, el método analiza inicialmente la desviación algebraica individual de cada observación \(Y_i\) con respecto a su valor teórico esperado:
\[ Y_i - (\beta_0 + \beta_1 X_i) \tag{1.7} \]
Explicación: El término \((\beta_0 + \beta_1 X_i)\) representa la función de regresión poblacional o la media de la variable de respuesta condicional a la observación del predictor \(X_i\). La diferencia geométrica constituye el error o desviación empírica de dicho punto.
Para evitar que las desviaciones positivas y negativas se cancelen mutuamente al agruparlas, el método define formalmente el criterio de optimización \(Q\), el cual consiste en la suma de los cuadrados de estas desviaciones para las \(n\) observaciones de la muestra:
\[ Q = \sum_{i=1}^{n} (Y_i - \beta_0 - \beta_1 X_i)^2 \tag{1.8} \]
Explicación paso a paso:
- \(\sum_{i=1}^{n}\): Operador sumatorio que agrega los resultados desde el primer sujeto (\(i=1\)) hasta el límite muestral (\(n\)).
- \(Y_i\): Valor real observado de la variable de respuesta para el individuo \(i\).
- \(\beta_0\): Intercepto de la función de regresión poblacional con el eje de las ordenadas.
- \(\beta_1\): Coeficiente de pendiente que mide el cambio esperado en \(Y\) ante una variación unitaria en \(X\).
- El exponente \(^2\) penaliza de forma cuadrática las desviaciones más grandes y asegura una superficie matemáticamente convexa para hallar un mínimo global único mediante cálculo diferencial (derivando \(Q\) respecto a \(\beta_0\) y \(\beta_1\)).
El método de mínimos cuadrados fundamenta la transición de la teoría abstracta a la inferencia empírica. El uso del criterio cuadrático \(Q\) es una elección deliberada que simplifica la manipulación analítica (frente al uso de valores absolutos), asegurando que los estimadores resultantes tengan propiedades estadísticas óptimas (estimadores lineales insesgados de mínima varianza o BLUE) bajo los supuestos clásicos de Gauss-Markov. Sin embargo, su vulnerabilidad intrínseca radica en que, al elevar los errores al cuadrado, el modelo es altamente sensible a valores atípicos (outliers), lo cual puede sesgar drásticamente la pendiente estimada en muestras pequeñas como la presentada en el ejemplo.
Figura 1-9 Ilustración del Criterio de Mínimos Cuadrados Q para el Ajuste de una Recta de Regresión - Estudio de Persistencia
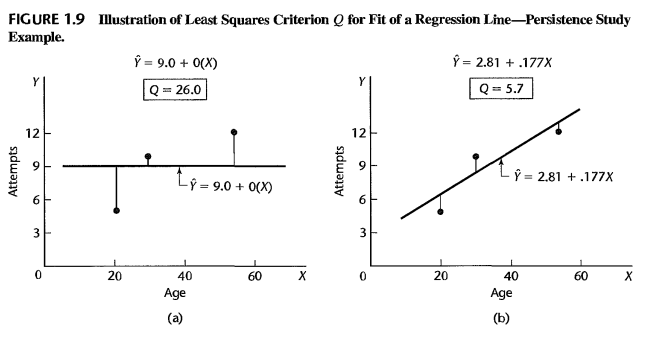
El fragmento analiza visual y numéricamente la aplicación práctica del criterio de mínimos cuadrados mediante el estudio de persistencia empírico con una muestra de tres casos (\(n = 3\)).
- Comparación de Modelos: Se evalúan dos rectas alternativas para ajustar los mismos datos muestrales. El primer modelo ignora la variable predictora \(X\) usando la media (\(\hat{Y} = 9.0 + 0(X)\)), mientras que el segundo modelo aplica los estimadores óptimos de mínimos cuadrados (\(\hat{Y} = 2.81 + .177X\)).
- Análisis Geométrico de las Desviaciones: Las gráficas ilustran de manera explícita cómo las desviaciones verticales individuales (la distancia entre el punto observado \(Y_i\) y el valor estimado en la recta \(\hat{Y}_i\)) se reducen drásticamente al utilizar la recta de mínimos cuadrados en lugar de la media aritmética simple.
- Minimización de Q: Se demuestra matemáticamente que una recta con mejor ajuste geométrico genera un valor acumulado del criterio cuadrático \(Q\) sustancialmente menor. El objetivo analítico del método concluye en la obtención de valores fijos para \(b_0\) y \(b_1\) que aseguren un mínimo global absoluto para dicha suma.